Simulations with UK Biobank genotypes and different effect structure across traits
Fabio Morgante & Deborah Kunkel
August 19, 2024
Last updated: 2024-08-19
Checks: 7 0
Knit directory: mr_mash_rss/
This reproducible R Markdown analysis was created with workflowr (version 1.7.0). The Checks tab describes the reproducibility checks that were applied when the results were created. The Past versions tab lists the development history.
Great! Since the R Markdown file has been committed to the Git repository, you know the exact version of the code that produced these results.
Great job! The global environment was empty. Objects defined in the global environment can affect the analysis in your R Markdown file in unknown ways. For reproduciblity it’s best to always run the code in an empty environment.
The command set.seed(20230612) was run prior to running
the code in the R Markdown file. Setting a seed ensures that any results
that rely on randomness, e.g. subsampling or permutations, are
reproducible.
Great job! Recording the operating system, R version, and package versions is critical for reproducibility.
Nice! There were no cached chunks for this analysis, so you can be confident that you successfully produced the results during this run.
Great job! Using relative paths to the files within your workflowr project makes it easier to run your code on other machines.
Great! You are using Git for version control. Tracking code development and connecting the code version to the results is critical for reproducibility.
The results in this page were generated with repository version 9c9b8d5. See the Past versions tab to see a history of the changes made to the R Markdown and HTML files.
Note that you need to be careful to ensure that all relevant files for
the analysis have been committed to Git prior to generating the results
(you can use wflow_publish or
wflow_git_commit). workflowr only checks the R Markdown
file, but you know if there are other scripts or data files that it
depends on. Below is the status of the Git repository when the results
were generated:
Ignored files:
Ignored: .snakemake/
Ignored: data/
Ignored: output/GWAS_for_regions/
Ignored: output/bayesC_fit/
Ignored: output/bayesR_fit/
Ignored: output/estimated_effects/
Ignored: output/kriging_rss_fit/
Ignored: output/ldpred2_auto_fit/
Ignored: output/ldpred2_auto_gwide_fit/
Ignored: output/ldsc_fit/
Ignored: output/misc/
Ignored: output/mr_mash_rss_fit/
Ignored: output/mtag_ldpred2_auto_fit/
Ignored: output/mtag_summary_statistics/
Ignored: output/mvbayesC_fit/
Ignored: output/prediction_accuracy/
Ignored: output/sblup_fit/
Ignored: output/summary_statistics/
Ignored: output/wmt_sblup_fit/
Ignored: run/
Ignored: tmp/
Untracked files:
Untracked: code/adjust_LD_test.R
Untracked: code/compute_sumstats_test_bc_ukb.R
Untracked: code/compute_sumstats_ukb_2.R
Untracked: code/fit_kriging_rss_ukb.R
Untracked: code/fit_mrmashrss_test_ukb.R
Untracked: code/match_sumstats_with_LD_ukb.R
Untracked: code/merge_sumstats_all_chr_ukb.R
Untracked: code/split_effects_by_chr_imp_ukb.R
Untracked: scripts/11_run_fit_mrmashrss_by_chr_V_all_chr_bc_ukb.sbatch
Untracked: scripts/11_run_fit_mrmashrss_sparse_LD_mvsusie_paper_prior_by_chr_bc_ukb.sbatch
Untracked: scripts/12_run_compute_pred_accuracy_mrmashrss_sparse_LD_mvsusie_paper_prior_bc_ukb.sbatch
Untracked: scripts/12_run_fit_mrmashrss_sparse_LD_Vcor_all_chr_init_by_chr_bc_ukb.sbatch
Untracked: scripts/13_run_compute_pred_accuracy_mrmashrss_sparse_LD_Vcor_all_chr_init_bc_ukb.sbatch
Untracked: scripts/3_run_compute_sumstats_by_chr_and_fold_test_bc_ukb.sbatch
Untracked: scripts/7_run_compute_residual_cor_all_chr_bc_ukb.sbatch
Untracked: scripts/run_adjust_LD_test.sbatch
Untracked: scripts/run_fit_kriging_rss_by_chr_and_trait_bc_ukb.sbatch
Untracked: vs_sm_convert/
Untracked: vs_sm_test/
Unstaged changes:
Modified: analysis/index.Rmd
Modified: ukb_sim_missing_pheno_equal_effects_indep_resid.yaml
Modified: ukb_sim_missing_pheno_snakemake_submitter.sh
Modified: ukb_sim_snakemake_submitter.sh
Note that any generated files, e.g. HTML, png, CSS, etc., are not included in this status report because it is ok for generated content to have uncommitted changes.
These are the previous versions of the repository in which changes were
made to the R Markdown (analysis/ukb_sim_results.Rmd) and
HTML (docs/ukb_sim_results.html) files. If you’ve
configured a remote Git repository (see ?wflow_git_remote),
click on the hyperlinks in the table below to view the files as they
were in that past version.
| File | Version | Author | Date | Message |
|---|---|---|---|---|
| html | 2a2f350 | fmorgante | 2024-08-12 | Build site. |
| Rmd | 0c5240d | fmorgante | 2024-08-12 | Update all results |
| html | 10e76a5 | fmorgante | 2024-07-23 | Build site. |
| Rmd | 62b5969 | fmorgante | 2024-07-23 | Remove BayesC results |
| html | cd5995e | fmorgante | 2024-07-23 | Build site. |
| Rmd | 45b66ae | fmorgante | 2024-07-23 | Add summary of results |
| html | 58afe0c | fmorgante | 2024-07-23 | Build site. |
| Rmd | 97da64c | fmorgante | 2024-07-23 | Add wMT-SBLUP results for the Equal Effects scenario |
| html | fe97ab8 | fmorgante | 2023-11-29 | Build site. |
| html | 3e70304 | fmorgante | 2023-11-28 | Build site. |
| Rmd | 9f3a235 | fmorgante | 2023-11-28 | Test 1 |
| html | c6733b1 | fmorgante | 2023-11-27 | Build site. |
| Rmd | d2ce723 | fmorgante | 2023-11-27 | Test |
| html | abef4f8 | fmorgante | 2023-11-27 | Build site. |
| html | 7e8092a | fmorgante | 2023-11-27 | Build site. |
| Rmd | 24968c6 | fmorgante | 2023-11-27 | Update results description |
| html | b4303c9 | fmorgante | 2023-11-27 | Build site. |
| Rmd | fcbbaee | fmorgante | 2023-11-27 | Add bayesC and mvbayesC_rest results |
| html | 7fb3e7f | fmorgante | 2023-11-21 | Build site. |
| Rmd | 1c76577 | fmorgante | 2023-11-21 | Update results and description |
| html | f8b39f9 | fmorgante | 2023-11-20 | Build site. |
| Rmd | ee794b5 | fmorgante | 2023-11-20 | Update results and description |
| html | a150b71 | fmorgante | 2023-11-19 | Build site. |
| Rmd | 39dbb0c | fmorgante | 2023-11-19 | Update results description |
| html | 3de96dc | fmorgante | 2023-11-19 | Build site. |
| Rmd | b69838a | fmorgante | 2023-11-19 | Update results |
| html | 834a67a | fmorgante | 2023-11-18 | Build site. |
| Rmd | cdd004d | fmorgante | 2023-11-18 | Update results |
| html | d9443c6 | fmorgante | 2023-11-18 | Build site. |
| html | 876699a | fmorgante | 2023-11-15 | Build site. |
| Rmd | 1ec1bc6 | fmorgante | 2023-11-15 | Update description of the results |
| html | 10a7465 | fmorgante | 2023-11-15 | Build site. |
| Rmd | 5a2fab8 | fmorgante | 2023-11-15 | Update plots |
| html | 18b92cc | fmorgante | 2023-11-15 | Build site. |
| html | fbca521 | fmorgante | 2023-11-14 | Build site. |
| Rmd | 4676825 | fmorgante | 2023-11-14 | Update description of the results |
| html | d669474 | fmorgante | 2023-11-14 | Build site. |
| html | 8778719 | fmorgante | 2023-11-14 | Build site. |
| html | 8b6d6bf | fmorgante | 2023-11-07 | Build site. |
| Rmd | 234f83b | fmorgante | 2023-11-07 | Fix additional typo |
| html | b5a6271 | fmorgante | 2023-11-07 | Build site. |
| Rmd | a5c4b2c | fmorgante | 2023-11-07 | Fix typo |
| html | 7e1e5e9 | fmorgante | 2023-11-07 | Build site. |
| Rmd | 0119ffa | fmorgante | 2023-11-07 | Add description of new methods |
| html | b0ded48 | fmorgante | 2023-11-07 | Build site. |
| Rmd | 10b51bd | fmorgante | 2023-11-07 | Add bayesR and mvbayesC results for equal effects scenario |
| html | 5e2df38 | fmorgante | 2023-11-02 | Build site. |
| Rmd | 61b27b1 | fmorgante | 2023-11-02 | Update results |
| html | d850539 | fmorgante | 2023-10-30 | Build site. |
| html | 7da29c7 | fmorgante | 2023-10-26 | Build site. |
| html | 7cd0ded | fmorgante | 2023-10-26 | Build site. |
| html | e6023d5 | fmorgante | 2023-10-26 | Build site. |
| Rmd | 63600cd | fmorgante | 2023-10-26 | Update general description and low PVE results |
| html | c77ab8f | fmorgante | 2023-10-21 | Build site. |
| html | e0b7f14 | fmorgante | 2023-10-20 | Build site. |
| html | eb09d7b | fmorgante | 2023-10-19 | Build site. |
| html | e8a2096 | fmorgante | 2023-10-18 | Build site. |
| Rmd | 2e7c7bd | fmorgante | 2023-10-18 | Update equal effects results |
| Rmd | 68bbbfc | fmorgante | 2023-10-02 | Minor changes |
| html | b5ea188 | fmorgante | 2023-08-04 | Build site. |
| Rmd | 324f45d | fmorgante | 2023-08-04 | Fix typo |
| html | 70e6d4a | fmorgante | 2023-08-04 | Build site. |
| Rmd | 1748dc9 | fmorgante | 2023-08-04 | Fix interpretation and graph |
| html | f38634b | fmorgante | 2023-08-04 | Build site. |
| Rmd | 7460ddc | fmorgante | 2023-08-04 | Add more polygenic scenario |
| html | a826a15 | fmorgante | 2023-07-31 | Build site. |
| Rmd | f0e1213 | fmorgante | 2023-07-31 | Add filtered plots |
| html | aa87dd0 | fmorgante | 2023-07-31 | Build site. |
| Rmd | 7c91a7c | fmorgante | 2023-07-31 | Fix bug |
| html | 33d8243 | fmorgante | 2023-07-31 | Build site. |
| Rmd | 31759a7 | fmorgante | 2023-07-31 | Add low PVE and 10 traits scenarios |
| html | 7b4d53c | fmorgante | 2023-07-31 | Build site. |
| Rmd | 36c46c0 | fmorgante | 2023-07-31 | Add bayesR |
| html | 9d82631 | fmorgante | 2023-06-28 | Build site. |
| Rmd | c34b451 | fmorgante | 2023-06-28 | Fix number |
| html | fd5c2b8 | fmorgante | 2023-06-28 | Build site. |
| Rmd | 84a9e87 | fmorgante | 2023-06-28 | Fix wording again |
| html | 8e716cf | fmorgante | 2023-06-28 | Build site. |
| Rmd | 21fdce5 | fmorgante | 2023-06-28 | Fix wording |
| html | ed4d773 | fmorgante | 2023-06-28 | Build site. |
| Rmd | 1b792ed | fmorgante | 2023-06-28 | Add a few more details |
| html | 3da045b | fmorgante | 2023-06-28 | Build site. |
| Rmd | 963fdb6 | fmorgante | 2023-06-28 | Add shared in subgroups scenario |
| html | 6469c43 | fmorgante | 2023-06-22 | Build site. |
| Rmd | 6327343 | fmorgante | 2023-06-22 | Minor change |
| html | 033b736 | fmorgante | 2023-06-22 | Build site. |
| Rmd | ee36241 | fmorgante | 2023-06-22 | Add mostly null scenario |
| html | 42fe7e0 | fmorgante | 2023-06-13 | Build site. |
| Rmd | 67a6127 | fmorgante | 2023-06-13 | Add another clarification |
| html | 1b1f3d6 | fmorgante | 2023-06-13 | Build site. |
| Rmd | d47b9bc | fmorgante | 2023-06-13 | Add clarification |
| html | 383a73f | fmorgante | 2023-06-13 | Build site. |
| Rmd | 3ecaea0 | fmorgante | 2023-06-13 | Minor improvements 2.0 |
| html | 9291d6d | fmorgante | 2023-06-13 | Build site. |
| Rmd | dad6412 | fmorgante | 2023-06-13 | Minor improvements |
| html | b4baad5 | fmorgante | 2023-06-13 | Build site. |
| Rmd | a222e7b | fmorgante | 2023-06-13 | Add more details |
| html | 409ae91 | fmorgante | 2023-06-12 | Build site. |
| Rmd | e56eb43 | fmorgante | 2023-06-12 | workflowr::wflow_publish("analysis/ukb_sim_results.Rmd") |
| html | 886b637 | fmorgante | 2023-06-12 | Build site. |
| Rmd | 2df5821 | fmorgante | 2023-06-12 | wflow_publish("analysis/ukb_sim_results.Rmd") |
###Load libraries
library(ggplot2)
library(cowplot)
repz <- 1:20
prefix <- "output/prediction_accuracy/ukb_caucasian_white_british_unrel_100000"
metric <- "r2"
traitz <- 1:5Introduction
The goal of this analysis is to benchmark the newly developed mr.mash.rss (aka mr.mash with summary data) against already existing methods in the task of predicting phenotypes from genotypes using only summary data. To do so, we used real genotypes from the array data of the UK Biobank. We randomly sampled 105,000 nominally unrelated (\(r_A\) < 0.025 between any pair) individuals of European ancestry (i.e., Caucasian and white British fields). After retaining variants with minor allele frequency (MAF) > 0.01, minor allele count (MAC) > 5, genotype missing rate < 0.1 and Hardy-Weinberg Equilibrium (HWE) test p-value > \(1 *10^{-10}\), our data consisted of 595,071 genetic variants (i.e., our predictors). Missing genotypes were imputed with the mean genotype for the respective genetic variant.
The linkage disequilibrium (LD) matrices (i.e., the correlation matrices) were computed using 146,288 nominally unrelated (\(r_A\) < 0.025 between any pair) individuals of European ancestry (i.e., Caucasian and white British fields), that did not overlap with the 105,000 individuals used for the rest of the analyses.
For each replicate, we simulated 5 traits (i.e., our responses) by randomly sampling 5,000 variants (out of the total of 595,071) to be causal, with different effect sharing structures across traits (see below). The genetic effects explain 50% of the total per-trait variance (except for two scenario as explained below) – in genetics terminology this is called genomic heritability (\(h_g^2\)). The residuals are uncorrelated across traits. Each trait was quantile normalized before all the analyses were performed.
We randomly sampled 5,000 (out of the 105,000) individuals to be the test set. The test set was only used to evaluate prediction accuracy. All the other steps were carried out on the training set of 100,000 individuals.
Summary statistics (i.e., effect size and its standard error) were obtained by univariate simple linear regression of each trait on each variant, one at a time. Variants were not standardized.
A few different methods were fitted:
- LDpred2 per-chromosome with the auto option, 1000 iterations (after 500 burn-in iterations), \(h^2\) initialized using an estimate from LD Score regression (LDSC) and \(p\) initialized using the same grid as in the original paper. NB this is a univariate method.
- mr.mash.rss per-chromosome, with both canonical and data-driven covariance matrices computed as described in the mvSuSiE paper, updating the (full rank) residual covariance and the mixture weights, without standardizing the variables. The residual covariance was initialized as in the mvSuSiE paper and the mixture weights were initialized as 90% of the weight on the null component and 10% of the weight split equally across the remaining components. The phenotypic covariance was computed as the sample covariance using the individual-level data. NB this is a multivariate method.
- BayesR per-chromosome, with 5000 iterations, 1000 burn-in iterations, thinning factor of 5, \(\pi\) (i.e., the proportion of causal variants) initialized as 0.0001, \(h^2\) initialized as 0.1, and other default parameters. NB this is a univariate method. We used the implementation in the qgg R package.
- mvBayesC per-chromosome, with 5000 iterations, 1000 burn-in iterations, thinning factor of 5, \(\pi\) (i.e., the proportion of causal variants) initialized as 0.0001, \(h^2\) initialized as 0.1, and other default parameters. NB this is a multivariate method. We used the implementation in the qgg R package.
- mvBayesCrest – a version of mvBayesC that only allows a variant to affect all or none of the traits – per-chromosome, with 5000 iterations, 1000 burn-in iterations, thinning factor of 5, \(\pi\) (i.e., the proportion of causal variants) initialized as 0.0001, \(h^2\) initialized as 0.1, and other default parameters. NB this is a multivariate method. We used the implementation in the qgg R package.
- wMT-SBLUP per-chromosome, with \(M_{eff}=60000\) and SBLUP estimate obtained with a window size of 2 Mb (using the SumTool R package implementation). NB this is a multivariate method. We used the implementation in the qgg R package.
- MTAG+LDpred2 with all variants. Because MTAG does not allow analyzing small indels and our data has a small numaber of those, we kept assigned the OLS estimates to those variants (instead of dropping them) before running LDpred2. LDpred2 was run with the same parameter as above, but with “shrink_corr=0.95” and “allow_jump_sign=FALSE” to avoid convergence issues. The effective sample size was estimated from the median \(\chi^2\) statistics of the OLS estimates and the MTAG estimates as done here. However, convergence issues still remained and some combinations of trait/replicate were dropped because of that.
Prediction accuracy was evaluated as the \(R^2\) of the regression of true phenotypes on the predicted phenotypes. This metric as the attractive property that its upper bound is \(h_g^2\).
20 replicates for each simulation scenario were run.
Equal effects scenario
In this scenario, the effects were drawn from a Multivariate Normal distribution with mean vector 0 and covariance matrix that achieves a per-trait variance of 1 and a correlation across traits of 1. This implies that the effects of the causal variants are equal across responses.
scenarioz <- "equal_effects_indep_resid"
methodz <- c("mr_mash_rss", "mvbayesC", "mvbayesC_rest", "wmt_sblup", "mtag_ldpred2_auto", "ldpred2_auto", "bayesR")
i <- 0
n_col <- 6
n_row <- length(repz) * length(scenarioz) * length(methodz) * length(traitz)
res <- as.data.frame(matrix(NA, ncol=n_col, nrow=n_row))
colnames(res) <- c("rep", "scenario", "method", "trait", "metric", "score")
for(sce in scenarioz){
for(met in methodz){
for(repp in repz){
dat <- readRDS(paste0(prefix, "_", sce, "_", met, "_pred_acc_", repp, ".rds"))
for(trait in traitz){
i <- i + 1
res[i, 1] <- repp
res[i, 2] <- sce
res[i, 3] <- met
res[i, 4] <- trait
res[i, 5] <- metric
res[i, 6] <- dat$r2[trait]
}
}
}
}
res <- transform(res, scenario=as.factor(scenario),
method=as.factor(method),
trait=as.factor(trait))
p_methods_shared <- ggplot(res, aes(x = trait, y = score, fill = method)) +
geom_boxplot(color = "black", outlier.size = 1, width = 0.85) +
stat_summary(fun=mean, geom="point", shape=23,
position = position_dodge2(width = 0.87,
preserve = "single")) +
ylim(0, 0.51) +
scale_fill_manual(values = c("pink", "red", "yellow", "orange", "green", "blue", "lightblue")) +
labs(x = "Trait", y = expression(italic(R)^2), fill="Method", title="") +
geom_hline(yintercept=0.5, linetype="dotted", linewidth=1, color = "black") +
theme_cowplot(font_size = 18)
print(p_methods_shared)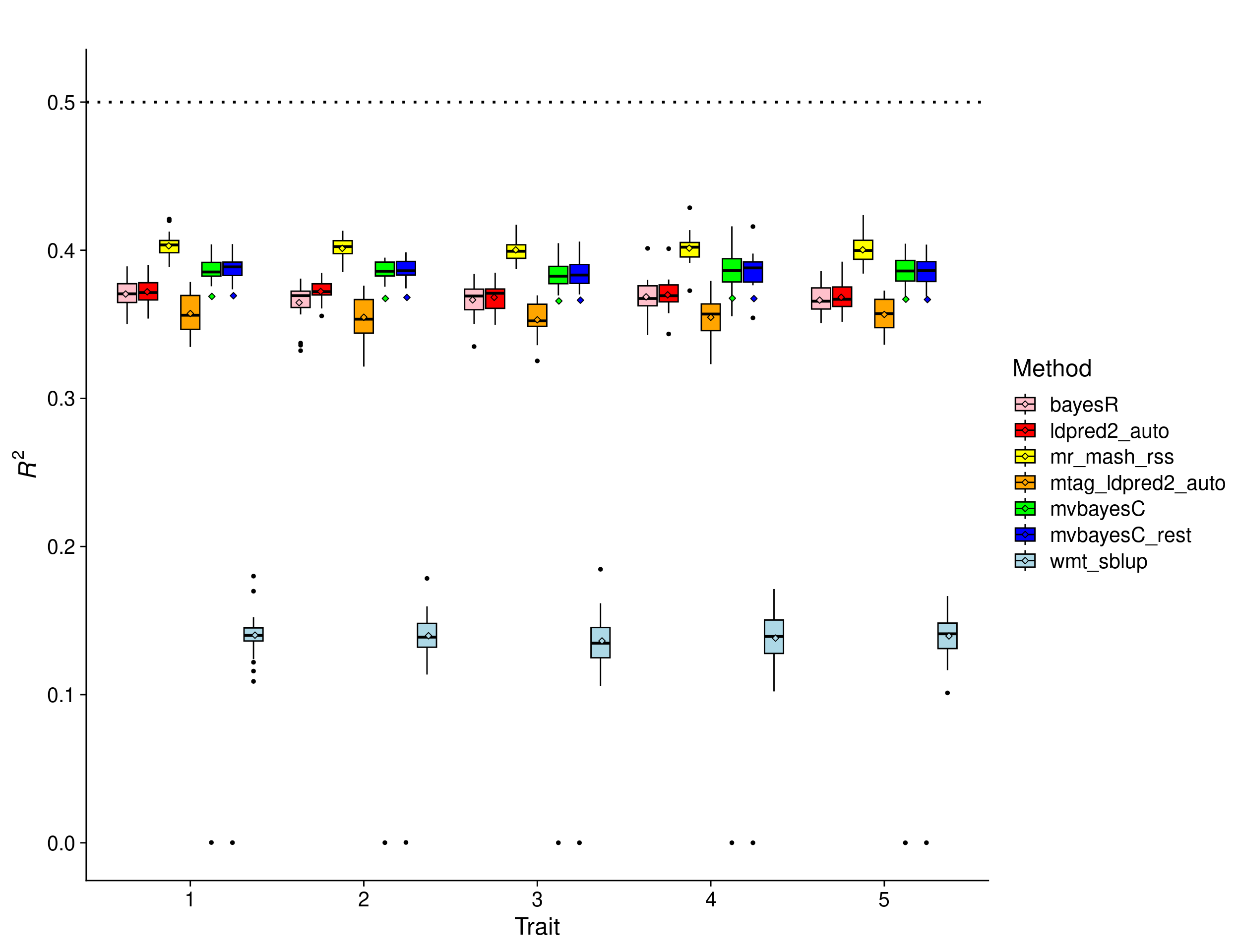
| Version | Author | Date |
|---|---|---|
| 2a2f350 | fmorgante | 2024-08-12 |
| 10e76a5 | fmorgante | 2024-07-23 |
| 58afe0c | fmorgante | 2024-07-23 |
| fe97ab8 | fmorgante | 2023-11-29 |
| 3e70304 | fmorgante | 2023-11-28 |
| c6733b1 | fmorgante | 2023-11-27 |
| abef4f8 | fmorgante | 2023-11-27 |
| b4303c9 | fmorgante | 2023-11-27 |
| d669474 | fmorgante | 2023-11-14 |
| 8778719 | fmorgante | 2023-11-14 |
| b0ded48 | fmorgante | 2023-11-07 |
| d850539 | fmorgante | 2023-10-30 |
| eb09d7b | fmorgante | 2023-10-19 |
| e8a2096 | fmorgante | 2023-10-18 |
| 33d8243 | fmorgante | 2023-07-31 |
| 383a73f | fmorgante | 2023-06-13 |
| 9291d6d | fmorgante | 2023-06-13 |
| b4baad5 | fmorgante | 2023-06-13 |
In this scenario, there is a clear advantage to using multivariate methods. In fact, given that the effects are equal across traits and the residuals are uncorrelated, a multivariate analysis is roughly equivalent to having 5 times as many samples as in an univariate analysis. As expected, the results show that mr.mash.rss clearly does better than LDpred2 auto BayesC, and BayesR, which perform similarly. mvBayesC (both versions) does better than the univariate methods, but not as well as mr.mash.rss. wMT-SBLUP does poorly as its infinitesimal architecture assumption is not well-suited for the true genetic architecture of the traits. MTAG+LDpred2 does a little worse than LDpred2, potentially because the method is designed to be used with OLS estimates.
Mostly null scenario
In this scenario, the effects were drawn from a Multivariate Normal distribution with mean vector 0 and covariance matrix that achieves effects (with variance 1) to be present only trait 1. The other 4 traits are only random noise.
scenarioz <- "trait_1_only_effects_indep_resid"
methodz <- c("mr_mash_rss", "mvbayesC", "mvbayesC_rest", "wmt_sblup", "mtag_ldpred2_auto", "ldpred2_auto", "bayesR")
i <- 0
n_col <- 6
n_row <- length(repz) * length(scenarioz) * length(methodz) * length(traitz)
res <- as.data.frame(matrix(NA, ncol=n_col, nrow=n_row))
colnames(res) <- c("rep", "scenario", "method", "trait", "metric", "score")
for(sce in scenarioz){
for(met in methodz){
for(repp in repz){
dat <- readRDS(paste0(prefix, "_", sce, "_", met, "_pred_acc_", repp, ".rds"))
for(trait in traitz){
i <- i + 1
res[i, 1] <- repp
res[i, 2] <- sce
res[i, 3] <- met
res[i, 4] <- trait
res[i, 5] <- metric
res[i, 6] <- dat$r2[trait]
}
}
}
}
res <- transform(res, scenario=as.factor(scenario),
method=as.factor(method),
trait=as.factor(trait))
p_mostly_null <- ggplot(res, aes(x = trait, y = score, fill = method)) +
geom_boxplot(color = "black", outlier.size = 1, width = 0.85) +
stat_summary(fun=mean, geom="point", shape=23,
position = position_dodge2(width = 0.87,
preserve = "single")) +
ylim(0.0, 0.51) +
scale_fill_manual(values = c("pink", "red", "yellow", "orange", "green", "blue", "lightblue")) +
labs(x = "Trait", y = expression(italic(R)^2), fill="Method", title="") +
geom_hline(yintercept=0.5, linetype="dotted", linewidth=1, color = "black") +
theme_cowplot(font_size = 18)
print(p_mostly_null)Warning: Removed 80 rows containing non-finite outside the scale range
(`stat_boxplot()`).Warning: Removed 80 rows containing non-finite outside the scale range
(`stat_summary()`).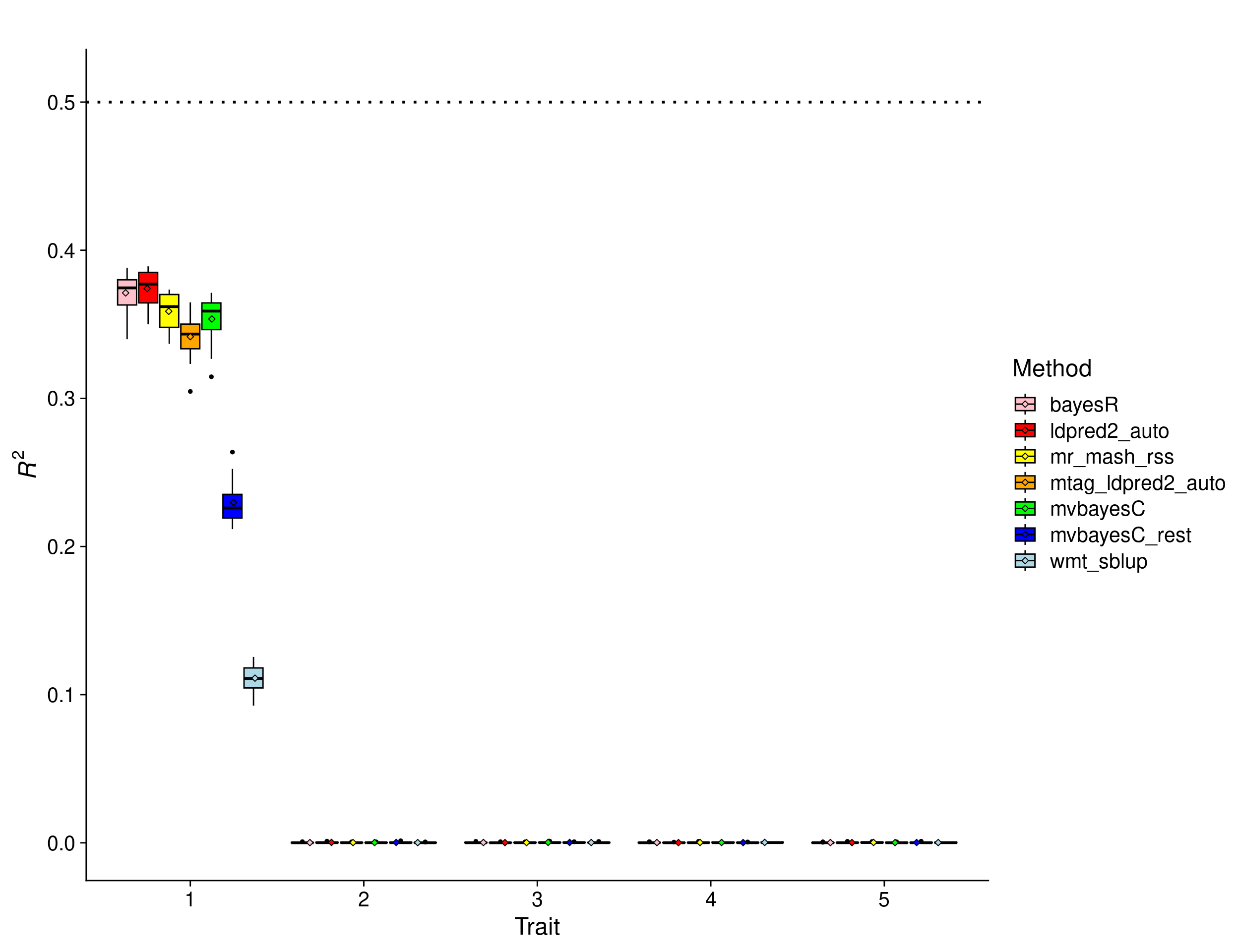
| Version | Author | Date |
|---|---|---|
| 2a2f350 | fmorgante | 2024-08-12 |
| 10e76a5 | fmorgante | 2024-07-23 |
| 3e70304 | fmorgante | 2023-11-28 |
| c6733b1 | fmorgante | 2023-11-27 |
| b4303c9 | fmorgante | 2023-11-27 |
| 10a7465 | fmorgante | 2023-11-15 |
| d850539 | fmorgante | 2023-10-30 |
| c77ab8f | fmorgante | 2023-10-21 |
| e8a2096 | fmorgante | 2023-10-18 |
| 33d8243 | fmorgante | 2023-07-31 |
| 7b4d53c | fmorgante | 2023-07-31 |
| 6469c43 | fmorgante | 2023-06-22 |
| 033b736 | fmorgante | 2023-06-22 |
In this scenario, there is no advantage to using multivariate methods. In fact, there is potential for multivariate methods to do worse than univariate methods because of the large amount of noise modeled jointly with the signal. The results show that mr.mash.rss can learn this structure from the data and performs similar to LDpred2 auto and BayesR, although a little worse. mvBayesC performs slightly worse than mr.mash.rss. mvBayesCrest and wMT-SBLUP cannot adapt well to this scenario, while MTAG+LDpred2 does better than them but worse than the other methods.
Shared in subgroups scenario
In this scenario, the effects were drawn from a mixture of two Multivariate Normal distributions, i.e., \(w_1 MVN(0, \Sigma_1) + w_2 MVN(0, \Sigma_2)\), where \(w_1\) = 0.5 and \(w_2\) = 0.5, \(\Sigma_1\) is such that it achieves correlation across traits of 0.9 and variance of 1, \(\Sigma_2\) is such that it achieves correlation across traits of 0.7 and variance of 1. The first component of the mixture applies to traits 1-3 while the second component applies to traits 4-5. The per-trait \(h^2_g\) is 0.3 for traits 1-3 and 0.5 for the traits 4-5.
scenarioz <- "blocks_shared_effects_indep_resid"
methodz <- c("mr_mash_rss", "mvbayesC", "mvbayesC_rest", "wmt_sblup", "mtag_ldpred2_auto", "ldpred2_auto", "bayesR")
i <- 0
n_col <- 6
n_row <- length(repz) * length(scenarioz) * length(methodz) * length(traitz)
res <- as.data.frame(matrix(NA, ncol=n_col, nrow=n_row))
colnames(res) <- c("rep", "scenario", "method", "trait", "metric", "score")
for(sce in scenarioz){
for(met in methodz){
for(repp in repz){
dat <- readRDS(paste0(prefix, "_", sce, "_", met, "_pred_acc_", repp, ".rds"))
for(trait in traitz){
i <- i + 1
res[i, 1] <- repp
res[i, 2] <- sce
res[i, 3] <- met
res[i, 4] <- trait
res[i, 5] <- metric
res[i, 6] <- dat$r2[trait]
}
}
}
}
res <- transform(res, scenario=as.factor(scenario),
method=as.factor(method),
trait=as.factor(trait))
p_blocks_shared <- ggplot(res, aes(x = trait, y = score, fill = method)) +
geom_boxplot(color = "black", outlier.size = 1, width = 0.85) +
stat_summary(fun=mean, geom="point", shape=23,
position = position_dodge2(width = 0.87,
preserve = "single")) +
ylim(0, 0.51) +
scale_fill_manual(values = c("pink", "red", "yellow", "orange", "green", "blue", "lightblue")) +
labs(x = "Trait", y = expression(italic(R)^2), fill="Method", title="") +
geom_hline(yintercept=0.5, linetype="dotted", linewidth=1, color = "black") +
geom_hline(yintercept=0.3, linetype="dashed", linewidth=1, color = "black") +
theme_cowplot(font_size = 18)
print(p_blocks_shared)Warning: Removed 2 rows containing non-finite outside the scale range
(`stat_boxplot()`).Warning: Removed 2 rows containing non-finite outside the scale range
(`stat_summary()`).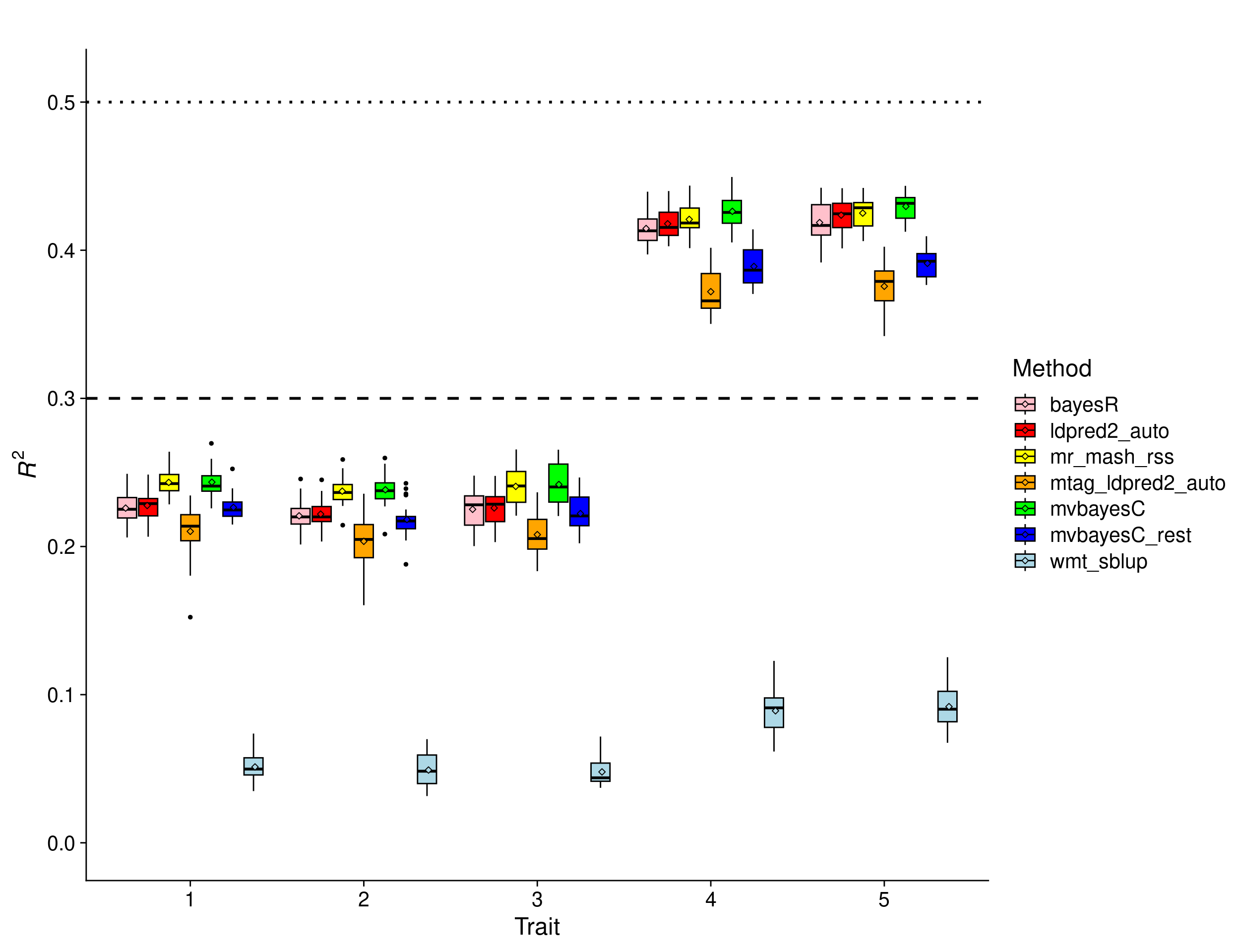
In this scenario, multivariate methods can have some advantage over univariate methods, provided that the former can adapt to the complex structure of the effects. The results show that all the methods perform very similarly in traits 3 and 4 – with mvBayesC being a tiny bit better – but mvBayesCrest. However, mr.mash.rss and mvBayesC methods perform better than the univariate methods and mvBayesCrest in traits 1-3, due to the higher effect correlation across traits, the larger number of traits with shared effects, and the smaller \(h^2_g\) (harder scenario for univariate methods). MTAG+LDpred2 performs worse than the other multivariate methods except for wMT-SBLUP, which is not well-suited for the true genetic architecture of the traits.
Equal effects scenario – low PVE
In this scenario, the effects were drawn from a Multivariate Normal distribution with mean vector 0 and covariance matrix that achieves a per-trait variance of 1 and a correlation across traits of 1. This implies that the effects of the causal variants are equal across responses. In addition, the per-trait genomic heritability was set to 0.2. In this scenario, \(h^2\) was initialized as 0.01 in BayesC, BayesR, mvBayesC and mvBayesCrest.
scenarioz <- "equal_effects_low_pve_indep_resid"
methodz <- c("mr_mash_rss", "mvbayesC", "mvbayesC_rest", "wmt_sblup", "mtag_ldpred2_auto", "ldpred2_auto", "bayesR")
i <- 0
n_col <- 6
n_row <- length(repz) * length(scenarioz) * length(methodz) * length(traitz)
res <- as.data.frame(matrix(NA, ncol=n_col, nrow=n_row))
colnames(res) <- c("rep", "scenario", "method", "trait", "metric", "score")
for(sce in scenarioz){
for(met in methodz){
for(repp in repz){
dat <- readRDS(paste0(prefix, "_", sce, "_", met, "_pred_acc_", repp, ".rds"))
for(trait in traitz){
i <- i + 1
res[i, 1] <- repp
res[i, 2] <- sce
res[i, 3] <- met
res[i, 4] <- trait
res[i, 5] <- metric
res[i, 6] <- dat$r2[trait]
}
}
}
}
res <- transform(res, scenario=as.factor(scenario),
method=as.factor(method),
trait=as.factor(trait))
p_methods_shared_lowpve <- ggplot(res, aes(x = trait, y = score, fill = method)) +
geom_boxplot(color = "black", outlier.size = 1, width = 0.85) +
stat_summary(fun=mean, geom="point", shape=23,
position = position_dodge2(width = 0.87,
preserve = "single")) +
ylim(0, 0.2) +
scale_fill_manual(values = c("pink", "red", "yellow", "orange", "green", "blue", "lightblue")) +
labs(x = "Trait", y = expression(italic(R)^2), fill="Method", title="") +
geom_hline(yintercept=0.2, linetype="dotted", linewidth=1, color = "black") +
theme_cowplot(font_size = 18)
print(p_methods_shared_lowpve)Warning: Removed 31 rows containing non-finite outside the scale range
(`stat_boxplot()`).Warning: Removed 31 rows containing non-finite outside the scale range
(`stat_summary()`).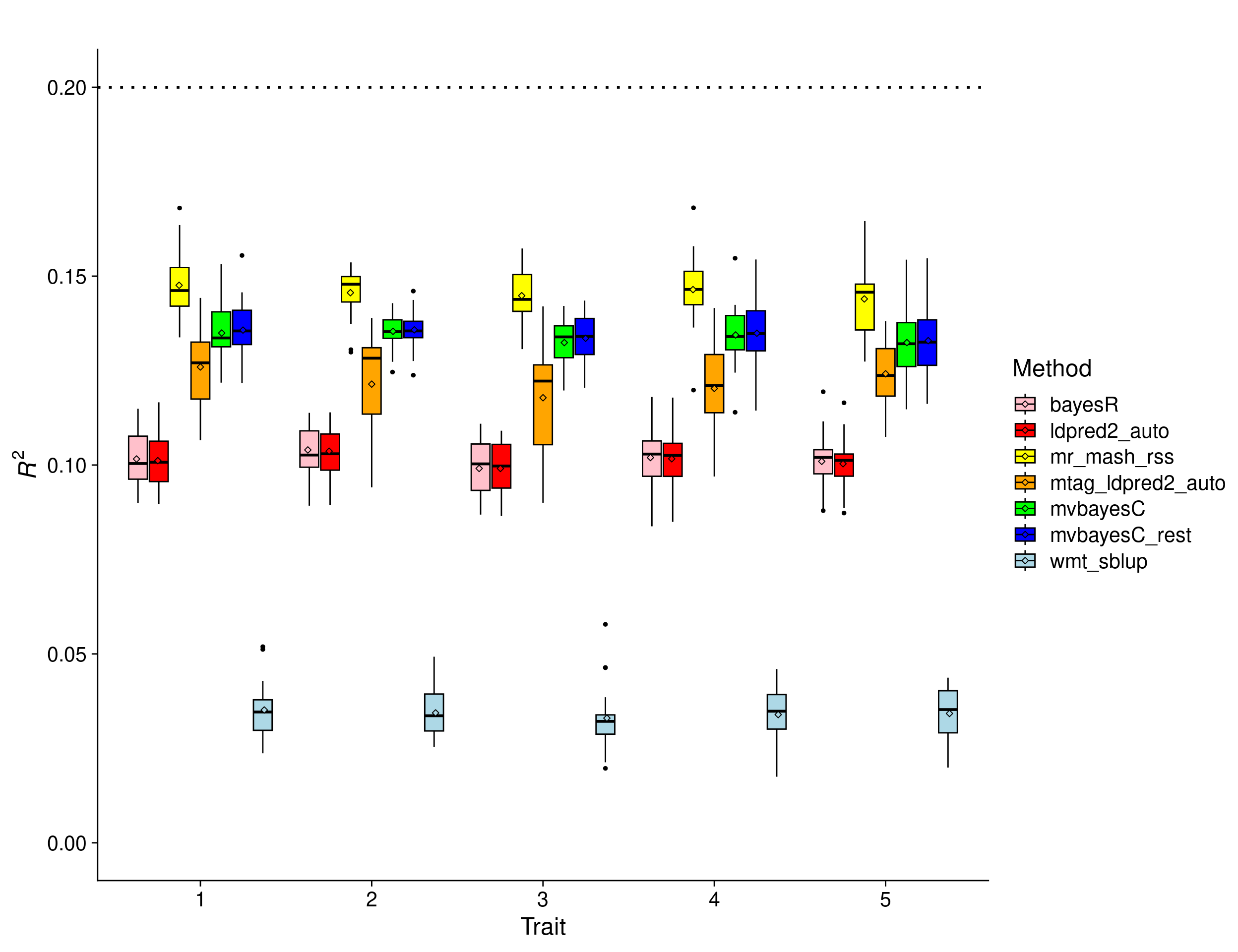
| Version | Author | Date |
|---|---|---|
| 2a2f350 | fmorgante | 2024-08-12 |
| 10e76a5 | fmorgante | 2024-07-23 |
| 3e70304 | fmorgante | 2023-11-28 |
| c6733b1 | fmorgante | 2023-11-27 |
| b4303c9 | fmorgante | 2023-11-27 |
| 834a67a | fmorgante | 2023-11-18 |
| 5e2df38 | fmorgante | 2023-11-02 |
| e6023d5 | fmorgante | 2023-10-26 |
| e8a2096 | fmorgante | 2023-10-18 |
| a826a15 | fmorgante | 2023-07-31 |
| 33d8243 | fmorgante | 2023-07-31 |
In this scenario, we expect the relative improvement of multivariate methods compared to univariate methods to be larger than with \(h^2_g = 0.5\). This is because with smaller signal-to-noise ratio, it is harder for univariate methods to estimate effects accurately. Multivariate methods can borrow information across traits (if effects are shared) and improve accuracy. The results show that the multivariate methods (including MTAG+LDpred2) outperform the univariate methods except for wMT-SBLUP, which is not well-suited for the true genetic architecture of the traits. mr.mash.rss achieves the highest accuracy.
Equal effects scenario – more polygenic
In this scenario, the effects were drawn from a Multivariate Normal distribution with mean vector 0 and covariance matrix that achieves a per-trait variance of 1 and a correlation across traits of 1. This implies that the effects of the causal variants are equal across responses. In addition, the number of causal variants was set to 50,000. In this scenario, \(\pi\) was initialized as 0.01 in BayesC, BayesR, mvBayesC, and mvBayesCrest.
scenarioz <- "equal_effects_50000causal_indep_resid"
methodz <- c("mr_mash_rss", "mvbayesC", "mvbayesC_rest", "wmt_sblup", "mtag_ldpred2_auto", "ldpred2_auto", "bayesR")
i <- 0
n_col <- 6
n_row <- length(repz) * length(scenarioz) * length(methodz) * length(traitz)
res <- as.data.frame(matrix(NA, ncol=n_col, nrow=n_row))
colnames(res) <- c("rep", "scenario", "method", "trait", "metric", "score")
for(sce in scenarioz){
for(met in methodz){
for(repp in repz){
dat <- readRDS(paste0(prefix, "_", sce, "_", met, "_pred_acc_", repp, ".rds"))
for(trait in traitz){
i <- i + 1
res[i, 1] <- repp
res[i, 2] <- sce
res[i, 3] <- met
res[i, 4] <- trait
res[i, 5] <- metric
res[i, 6] <- dat$r2[trait]
}
}
}
}
res <- transform(res, scenario=as.factor(scenario),
method=as.factor(method),
trait=as.factor(trait))
p_methods_more_poly <- ggplot(res, aes(x = trait, y = score, fill = method)) +
geom_boxplot(color = "black", outlier.size = 1, width = 0.85) +
stat_summary(fun=mean, geom="point", shape=23,
position = position_dodge2(width = 0.87,
preserve = "single")) +
ylim(0, 0.5) +
scale_fill_manual(values = c("pink", "red", "yellow", "orange", "green", "blue", "lightblue")) +
labs(x = "Trait", y = expression(italic(R)^2), fill="Method", title="") +
geom_hline(yintercept=0.5, linetype="dotted", linewidth=1, color = "black") +
theme_cowplot(font_size = 18)
print(p_methods_more_poly)Warning: Removed 74 rows containing non-finite outside the scale range
(`stat_boxplot()`).Warning: Removed 74 rows containing non-finite outside the scale range
(`stat_summary()`).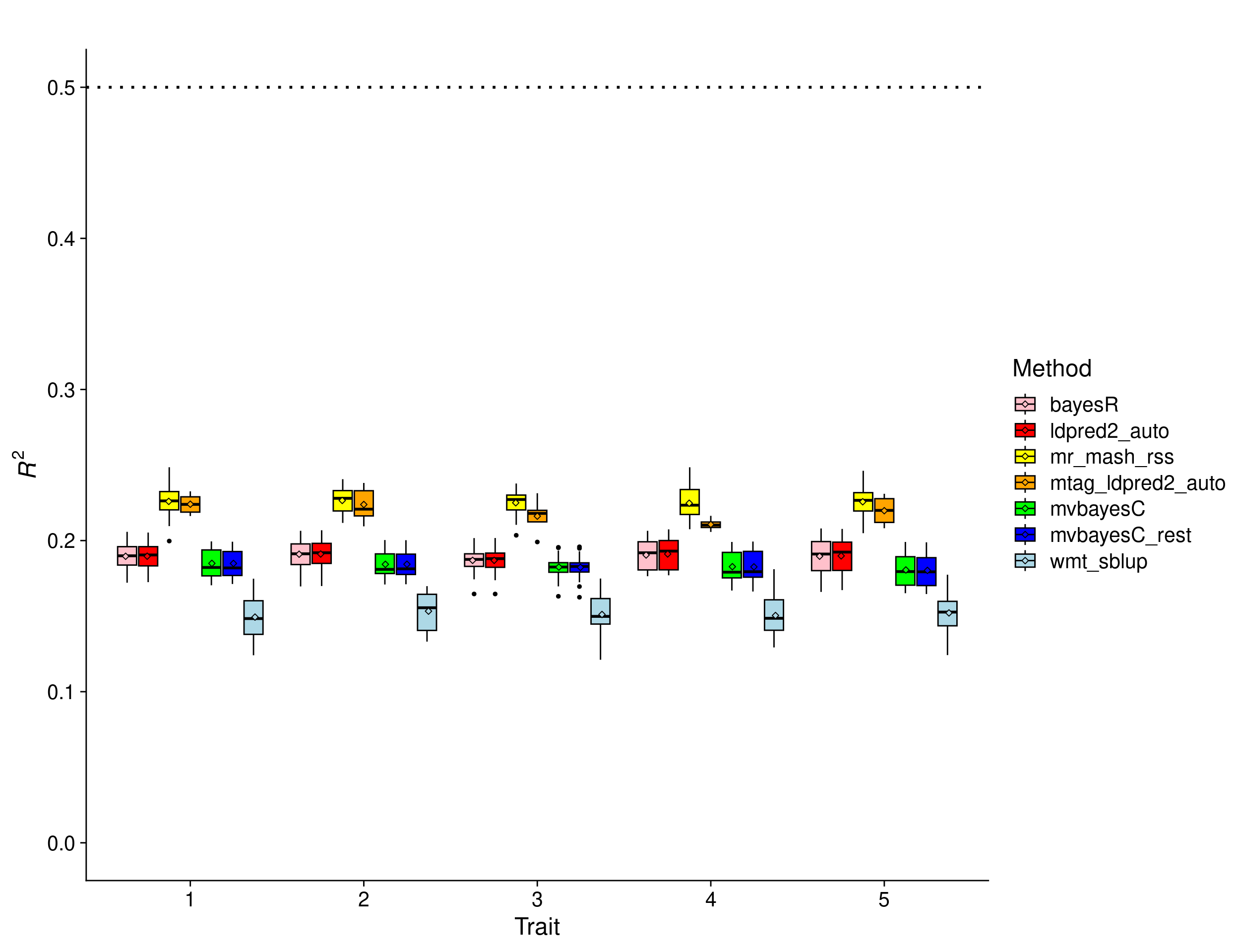
| Version | Author | Date |
|---|---|---|
| 2a2f350 | fmorgante | 2024-08-12 |
| 10e76a5 | fmorgante | 2024-07-23 |
| 3e70304 | fmorgante | 2023-11-28 |
| c6733b1 | fmorgante | 2023-11-27 |
| b4303c9 | fmorgante | 2023-11-27 |
| 7fb3e7f | fmorgante | 2023-11-21 |
| 3de96dc | fmorgante | 2023-11-19 |
| 5e2df38 | fmorgante | 2023-11-02 |
| 70e6d4a | fmorgante | 2023-08-04 |
| f38634b | fmorgante | 2023-08-04 |
In this scenario, we expect the accuracy to be lower because of the much larger number of causal variants, each explaining a much lower proportion of the total \(h^2_g=0.5\). Multivariate methods can borrow information across traits (if effects are shared) and improve accuracy. The results show that mr.mash.rss clearly does better than the univariate methods in this scenario too. MTAG+LDpred2 also performs really well in this scenario. mvBayesC (both versions) seems to have difficulties in this scenario. wMT-SBLUP is not well-suited for the true genetic architecture of the traits.
Equal effects scenario – 10 traits
In this scenario, the effects were drawn from a Multivariate Normal distribution with mean vector 0 and covariance matrix that achieves a per-trait variance of 1 and a correlation across traits of 1. This implies that the effects of the causal variants are equal across responses. In addition, the number of traits was increased to 10.
scenarioz <- "equal_effects_10traits_indep_resid"
methodz <- c("mr_mash_rss", "mvbayesC_rest", "wmt_sblup", "mtag_ldpred2_auto", "ldpred2_auto", "bayesR")
i <- 0
traitz <- 1:10
n_col <- 6
n_row <- length(repz) * length(scenarioz) * length(methodz) * length(traitz)
res <- as.data.frame(matrix(NA, ncol=n_col, nrow=n_row))
colnames(res) <- c("rep", "scenario", "method", "trait", "metric", "score")
for(sce in scenarioz){
for(met in methodz){
for(repp in repz){
dat <- readRDS(paste0(prefix, "_", sce, "_", met, "_pred_acc_", repp, ".rds"))
for(trait in traitz){
i <- i + 1
res[i, 1] <- repp
res[i, 2] <- sce
res[i, 3] <- met
res[i, 4] <- trait
res[i, 5] <- metric
res[i, 6] <- dat$r2[trait]
}
}
}
}
res <- transform(res, scenario=as.factor(scenario),
method=as.factor(method),
trait=as.factor(trait))
p_methods_shared_10traits <- ggplot(res, aes(x = trait, y = score, fill = method)) +
geom_boxplot(color = "black", outlier.size = 1, width = 0.85) +
stat_summary(fun=mean, geom="point", shape=23,
position = position_dodge2(width = 0.87,
preserve = "single")) +
ylim(0, 0.51) +
scale_fill_manual(values = c("pink", "red", "yellow", "orange", "blue", "lightblue")) +
labs(x = "Trait", y = expression(italic(R)^2), fill="Method", title="") +
geom_hline(yintercept=0.5, linetype="dotted", linewidth=1, color = "black") +
theme_cowplot(font_size = 18)
print(p_methods_shared_10traits)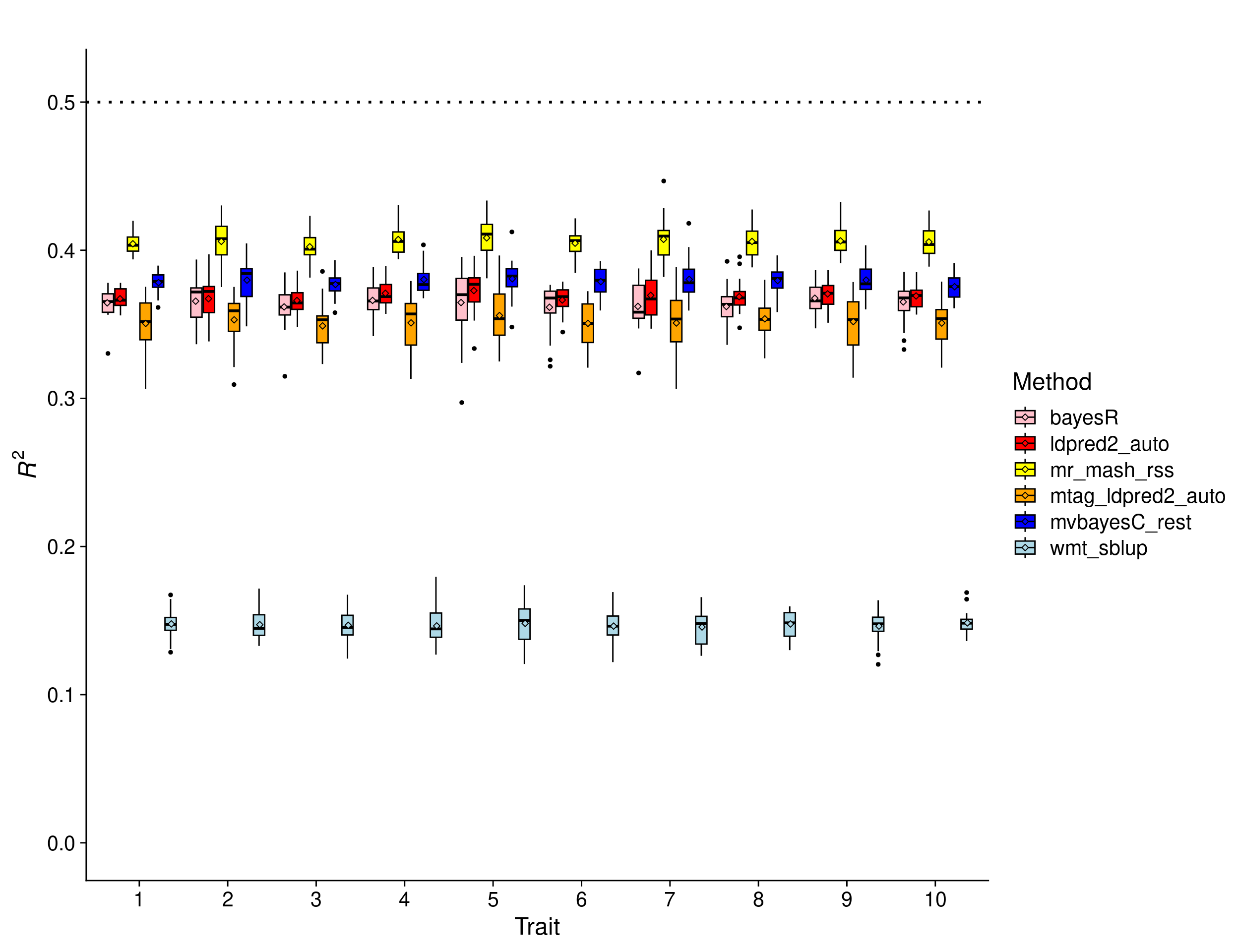
| Version | Author | Date |
|---|---|---|
| 2a2f350 | fmorgante | 2024-08-12 |
| 10e76a5 | fmorgante | 2024-07-23 |
| b4303c9 | fmorgante | 2023-11-27 |
| f8b39f9 | fmorgante | 2023-11-20 |
| 5e2df38 | fmorgante | 2023-11-02 |
| d850539 | fmorgante | 2023-10-30 |
| 7cd0ded | fmorgante | 2023-10-26 |
| e8a2096 | fmorgante | 2023-10-18 |
| a826a15 | fmorgante | 2023-07-31 |
| 33d8243 | fmorgante | 2023-07-31 |
In this scenario, we expect the relative improvement of multivariate methods compared to univariate methods to be a little larger than with 5 traits. This is because multivariate methods can borrow information across a larger number of traits (if effects are shared) and improve accuracy. The results show that mr.mash.rss clearly does better than the univariate methods, but the improvement compared to the scenario with 5 traits is small. mvBayesCrest does better than the univariate methods but worse than mr.mash.rss. mvBayesC is currently too slow to be run in this scenario. wMT-SBLUP is not well-suited for the true genetic architecture of the traits.
sessionInfo()R version 4.1.2 (2021-11-01)
Platform: x86_64-pc-linux-gnu (64-bit)
Running under: Rocky Linux 8.5 (Green Obsidian)
Matrix products: default
BLAS/LAPACK: /opt/ohpc/pub/libs/gnu9/openblas/0.3.7/lib/libopenblasp-r0.3.7.so
locale:
[1] LC_CTYPE=en_US.UTF-8 LC_NUMERIC=C
[3] LC_TIME=en_US.UTF-8 LC_COLLATE=en_US.UTF-8
[5] LC_MONETARY=en_US.UTF-8 LC_MESSAGES=en_US.UTF-8
[7] LC_PAPER=en_US.UTF-8 LC_NAME=C
[9] LC_ADDRESS=C LC_TELEPHONE=C
[11] LC_MEASUREMENT=en_US.UTF-8 LC_IDENTIFICATION=C
attached base packages:
[1] stats graphics grDevices utils datasets methods base
other attached packages:
[1] cowplot_1.1.3 ggplot2_3.5.1
loaded via a namespace (and not attached):
[1] Rcpp_1.0.13 highr_0.11 pillar_1.9.0 compiler_4.1.2
[5] bslib_0.7.0 later_1.3.2 jquerylib_0.1.4 git2r_0.32.0
[9] workflowr_1.7.0 tools_4.1.2 digest_0.6.35 gtable_0.3.5
[13] jsonlite_1.8.8 evaluate_0.23 lifecycle_1.0.4 tibble_3.2.1
[17] pkgconfig_2.0.3 rlang_1.1.4 cli_3.6.2 rstudioapi_0.16.0
[21] yaml_2.3.8 xfun_0.44 fastmap_1.2.0 withr_3.0.0
[25] dplyr_1.1.4 stringr_1.5.1 knitr_1.47 generics_0.1.3
[29] fs_1.6.4 vctrs_0.6.5 sass_0.4.9 tidyselect_1.2.1
[33] rprojroot_2.0.4 grid_4.1.2 glue_1.7.0 R6_2.5.1
[37] fansi_1.0.6 rmarkdown_2.27 farver_2.1.2 magrittr_2.0.3
[41] whisker_0.4.1 scales_1.3.0 promises_1.3.0 htmltools_0.5.8.1
[45] colorspace_2.1-0 httpuv_1.6.11 labeling_0.4.3 utf8_1.2.4
[49] stringi_1.8.4 munsell_0.5.1 cachem_1.1.0